Billion-Scale Speed
Pinecone delivers millisecond search latency even when querying across billions of high-dimensional vectors, ensuring your AI responds instantly.

AI DATA INFRASTRUCTURE
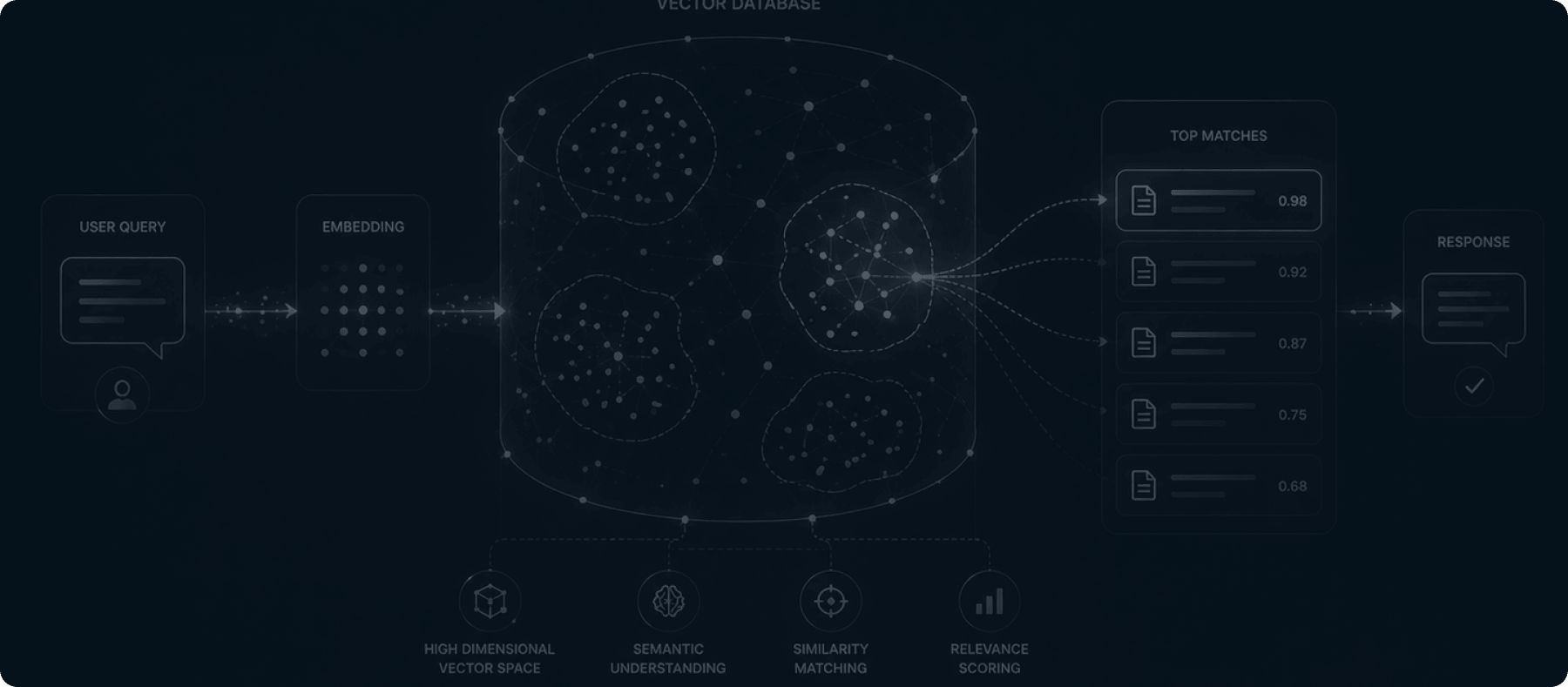
The intelligence of your AI is limited by how it stores and retrieves data. Deploy our Pinecone and vector database architects to build lightning-fast, highly accurate semantic search layers.

Pod Advantage
Standard SQL databases cannot handle the complexity of generative AI. Our data architects specialize in converting your unstructured enterprise data—PDFs, internal wikis, and chat logs—into high-dimensional vector embeddings, allowing your AI to instantly retrieve the exact context it needs with millisecond latency.
The Strategic Rationale
Pinecone delivers millisecond search latency even when querying across billions of high-dimensional vectors, ensuring your AI responds instantly.
It is a serverless, fully managed vector database. This drastically reduces your DevOps overhead and guarantees high availability for production environments.
As your enterprise data changes, Pinecone allows our pipelines to instantly update the vector embeddings, ensuring your AI is always reasoning over the most current information.
Technical DNA
Building enterprise-grade AI requires a sophisticated vector architecture that balances performance, cost, and absolute data privacy.