Absolute Data Privacy
Because the model is hosted entirely on your own servers, your sensitive corporate data never leaves your infrastructure, automatically satisfying stringent legal and compliance requirements.

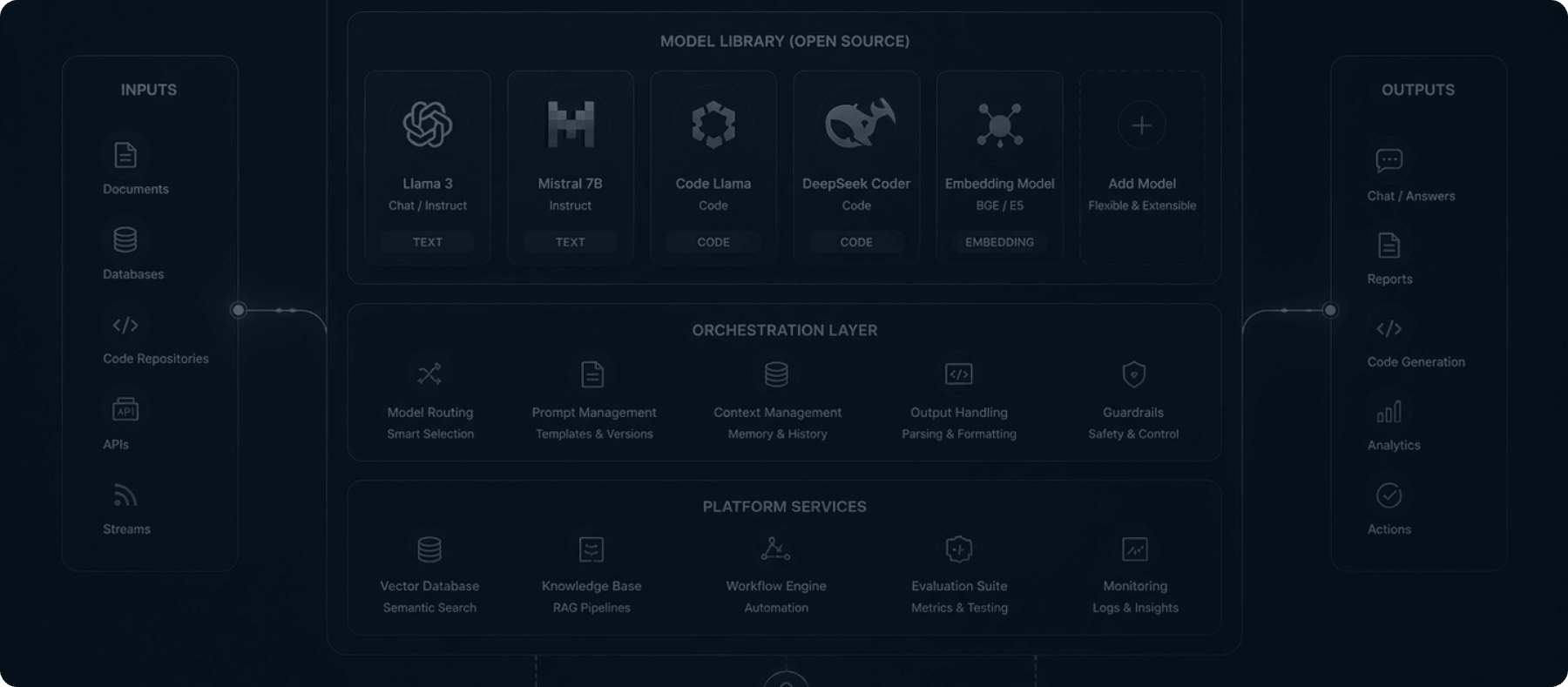
OPEN-SOURCE AI INFRASTRUCTURE
Break free from third-party API dependencies. Deploy elite engineers who download, fine-tune, and host the world's most powerful open-source models directly on your private enterprise infrastructure.

Pod Advantage
Relying on public APIs means sending your proprietary corporate data over the wire. Our Hugging Face deployment pods eliminate this risk. We specialize in provisioning private GPU clusters and deploying top-tier open-source models—like Llama 3 and Mistral—entirely within your isolated Virtual Private Cloud (VPC), ensuring absolute data sovereignty.
The Strategic Rationale
Because the model is hosted entirely on your own servers, your sensitive corporate data never leaves your infrastructure, automatically satisfying stringent legal and compliance requirements.
By moving away from usage-based pricing models like OpenAI or Anthropic, you eliminate unpredictable token costs and stabilize your AI operating budget, no matter how much you scale.
Open-source access allows our engineers to fundamentally alter the model's weights (using techniques like LoRA) so it becomes an absolute expert in your highly specific corporate terminology and internal processes.
Technical DNA
Deploying open-source models at scale requires a deep understanding of distributed inference, parameter-efficient fine-tuning, and hardware acceleration.